To
analyze the claim we will "grow" a decision tree. Decision trees
are a wonderful little device for analyzing anything with two possible
outcomes. Every time we reach the end of a branch and have
two
possibilities we simply create a set of two new branches. For our
analysis, we will assume that 2% of all employees actually use drugs. This
is lower than the general population but keep in mind that a lot of drug
users are unemployed. Also, a company with a clearly stated anti-drug policy
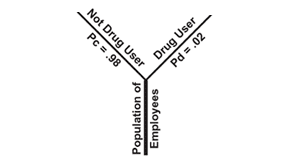
will probably have a low proportion of users. The tree's trunk represents
the population of all employees. The first set of branches (see figure 1)
represent the two possible conditions: drug user, not drug user. The
expression Pd = .02 indicates that there is a 2% probability of
a person being a drug user. Pc = .98 indicates a 98%
probability that a person is clean or drug free.
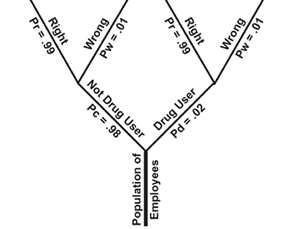
Next, we add two sets of branches representing the
drug test* as shown in figure 2 . One set of branches is attached to each of
the original two branches. Pw = .01 indicates that there is a
1% chance of getting a wrong or incorrect result from the test. Pr
= .99 indicates that there is a 99% chance of getting a right or correct
result from the test. Note that the probabilities associated with each set
of branches must add up to 100%.
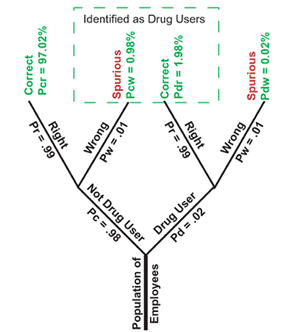
Finally we add the tree's leaves (see figure 3). Each
leaf represents a possible final outcome of the entire process. Note that
there are four possibilities. Two of the four possibilities are correct:
drug users and drug free individuals are both correctly identified.
However, two of the four possibilities are spurious: drug users and drug
free individuals are not correctly identified. We are unlikely to hear
complaints from a drug user who is incorrectly identified as being drug
free. The drug free person identified as a user is another matter. This
would be a very upsetting situation.
To find the probability of each final outcome as
represented by the four leaves simply multiply the probabilities of
each branch one must "climb" on the way to reaching the leaf.
For example, the probability of a drug user being rightly identified is
represented as Pdr and is calculated as follows:
Pdr = Pd * Pr
= 0.02 *
0.99
= 0.0198 or
1.98%
Note that all the leaf probabilities have to add up to
100%.
The population of people identified as drug users
consists of individuals who actually are drug users (1.98% of the
employees tested) and incorrectly identified individuals who actually are
not drug users (0.98% of the employees tested). The percentage of people
identified as drug users who are actually innocent can be calculated as
follows:
Pinnocent = Pcw /( Pcw
+Pdr )
= (0.98%) /(0.98% + 1.98%)
= .331 or 33.1%
The wild eyed claim that a third of all people accused
of drug use will be innocent is not so ridiculous after all.
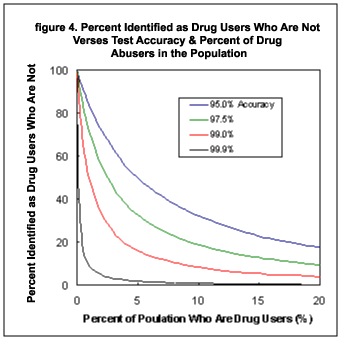
Figure 4 shows that the proportion of spurious results
among people identified as drug users is surprisingly sensitive to test
accuracy. An accuracy of 99% is marginal at best. However the biggest
surprise is the fact that the proportion of spurious results among people
failing drug tests approaches 100% as the proportion of drug users in the
general population approaches zero. Drug testing in a drug free population
amounts to a witch hunt.
|